
Symfony offre au développeur PHP une grande souplesse et une puissance certaine. Malgré cela, comme tout outil, il peut être mal utilisé s’il est mal compris, conduisant parfois des projets dans des situations délicates où l’urgence de la production fait inexorablement gonfler la dette technique. Et cette dette technique, elle se paye à terme beaucoup plus cher que l’investissement de départ !
Dans cette présentation, Jérôme Vieilledent a mis en valeur les vertus d’une architecture logicielle réfléchie et pragmatique, exemples réels à l’appui. Il a montré les outils que Symfony met à notre disposition pour y arriver, les design patterns mis en œuvre et les pièges à éviter. Les « buzzwords » SOLID, KISS, DRY et autres DDD ont alors pris tout leur sens !
Lien : https://speakerdeck.com/lolautruche/architecture-inutile
[su_spacer]
Qu’est-ce que l’architecture?
Pour démarrer, Jérôme nous a donné la définition Wikipedia de ce qu’est l’architecture :
L’architecture est l’art majeur de concevoir des espace et de bâtir des édifices, en respectant des règles de construction empiriques ou scientifiques, ainsi que des concepts esthétiques, classiques ou nouveaux, de forme et d’agencement d’espace, en y incluant les aspects sociaux et environnementaux liés à la fonction de l’édifice et à son intégration dans son environnement, quelle que soit cette fonction.
Pour lui, lors de la conception d’une architecture, on recherche l’harmonie, la stabilité.
C’est donc tout naturellement qu’il nous a livré la définition Wikipedia de l’architecture logicielle :
L’architecture logicielle décrit d’une manière symbolique et schématique les différents éléments d’un ou de plusieurs systèmes informatiques, leurs interrelations et leurs interactions. Contrairement aux spécifications produites par l’analyse fonctionnelle, le modèle d’architecture, produit lors de la phase de conception, ne décrit pas ce que doit réaliser un système informatique mais plutôt comment il doit être conçu de manière à répondre aux spécifications. L’analyse décrit le « quoi faire » alors que l’architecture décrit le « comment le faire »
Il a rapidement rappelé les principes Merise et UML, qui ont certes leur utilité, mais qui n’étaient pas le sujet qui nous intéressait ici.
Selon lui, le but de l’architecture logicielle est d’éviter une conception bancale.
Pour continuer à faire le parallèle entre l’architecture telle que tout le monde la connaît et l’architecture logicielle, il a comparé des ordres architecturaux, qui ont des normes à suivre (chacun a un objectif dans ses proportions ou ornementation, qui leur apportent robustesse et force). Il s’agit du même principe en architecture logicielle.
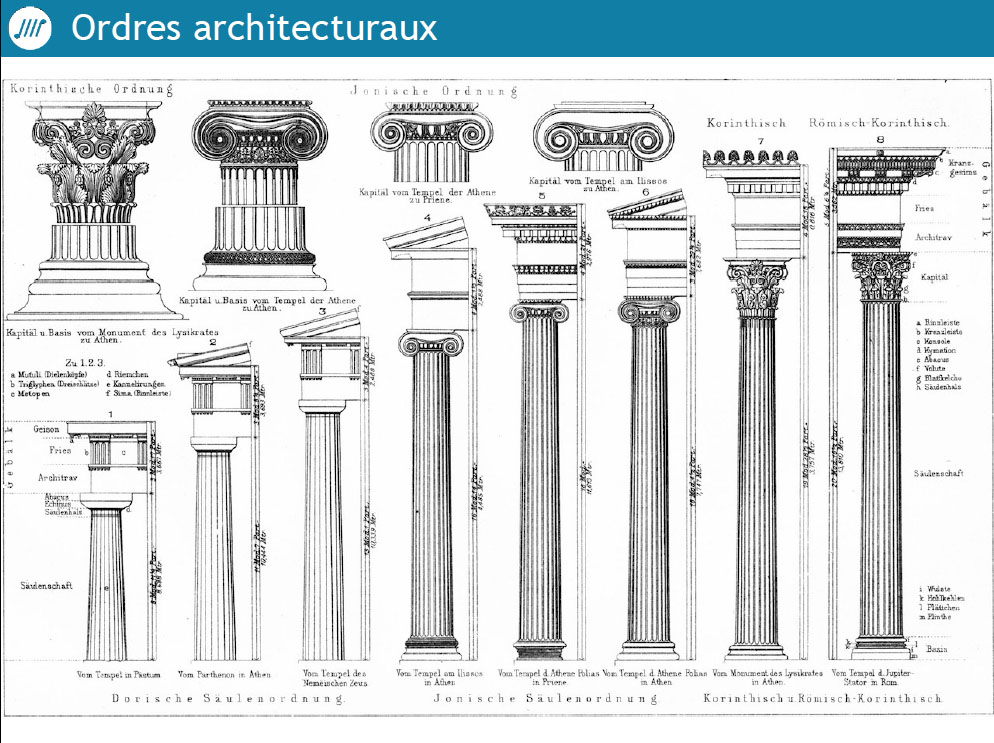
[su_spacer]
L’évolution de l’architecture des dernières années
Au fil des années, les principes d’architecture ont évolué :
- 1990 : spaghetti-oriented architecture (copier-coller) (Qui a dit WordPress?)
- 2000 : lasagna oriented architecture (monolithe à couche)
- 2010 : ravioli oriented architecture (micro-services). Un peu difficile à agréger.

PHP a malheureusement cette image de spaghetti (pas professionnel, présentant des incohérences).
L’idée est de trouver le bon équilibre, de rester agile. Comme dit plus haut, PHP a l’avantage d’offrir une réelle souplesse. Le but est d’apprendre à coder en PHP en rendant l’édifice SOLID (opposé à STUPID)
- Single responsibility : un composant fait une et une seule tâche
- Open/Closed : une classe doit être ouverte à l’extension mais fermée à la modification. Tous les attributs doivent être privés. Il est préférable d’utiliser la composition plutôt que l’héritage direct
- Liskov subtitution principle : ce principe vient de la première femme décorée en informatique (Liskov). Il s’agit de pouvoir remplacer un composant par une de ses sous classes (en relation avec l’interface). Conserver les exceptions, par exemple.
- Interface seggregation principle : préférer de petites interfaces spécifiques plutôt qu’une grosse générale. Le RouterInterface de Symfony2/3 en est un très bon exemple.
- Dependency inversion principle : dépendre d’abstractions, et pas d’implémentations. Le but est de partir des besoins applicatifs. Par exemple, définir des API dont on va se servir. Quels seront nos points d’entrée ? Ces points d’entrée feront appel à des couches plus basses pour gérer le plus bas niveau.
[su_spacer]
Des principes simples
Jérôme nous a ensuite rappelé des principes simples de programmation : DRY et KISS (étonnamment, pas YAGNI)
DRY : Don’t repeat yourself. C’est un travers que l’on a souvent. Il est important d’être générique
KISS : Keep it simple, stupid ! De manière générale, restons simple pour la maintenance
[su_spacer]
Un code spaghetti
Ensuite, un code spaghetti de 300 lignes, complexe, faisant appel à de nombreuses fonctions PHP sur les array (is_array, array_intersect_key, array_flip, array_merge, array_key_exists), des variables statiques, des fonctions statiques a été présenté. Inutile de dire que nous avons tous déjà travaillé sur un tel code.
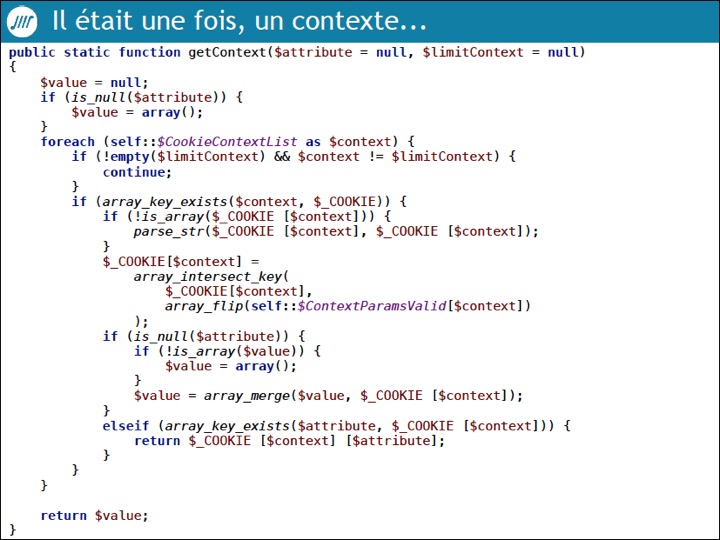
Le couperet est rapidement tombé : violation des couches, variables globales, conditions et config multipliées dans un fichier. La logique métier est mélangée à la session, puis le contexte est mis à jour. Rien de ce code ne respecte les principes SOLID.
Les conséquences sont sans appel:
- Complexité importante
- Maintenabilité difficile
- Evolutivité très risquée (complexité cyclomatique)
La plus grosse conséquence d’un tel code : la dette technique :
- Le code est instable, les corrections peuvent induire des régressions.
- La dette doit pouvoir être contrôlée et maîtrisée. Elle doit pouvoir être remboursée rapidement (refactoring)
[su_spacer]
La refactorisation par la DDD
C’est là que la DDD (Domain Driven Design) entre en jeu pour refactoriser. Le but du DDD est de nommer les choses, de les identifier et d’identifier leurs interactions.
En premier lieu, il faut redéfinir les caractéristiques du contexte :
- Il peut ne pas être unique
- Lié à la request (cookie)
- Il doit être à la disposition du code métier
Ces contextes contiennent des attributs:
- Les informations doivent être disponibles dans un contexte
- Ils peuvent être mis à jour
- Il est possible de faire du mapping, du filtrage à la mise à jour
- Il est possible d’appliquer des règles métier
Pour la refactorisation, il faudra :
- Définir un contexte qui aura comme value object. Les attributs seront les « propriétés » du contexte.
- Avoir un ContextFatory qui va construire les contextes depuis la request qui appellera des builders (un builder sera associé à un contexte)
- Avoir un ContextProvider qui sera un service fournissant les contextes/attributs
[su_spacer]
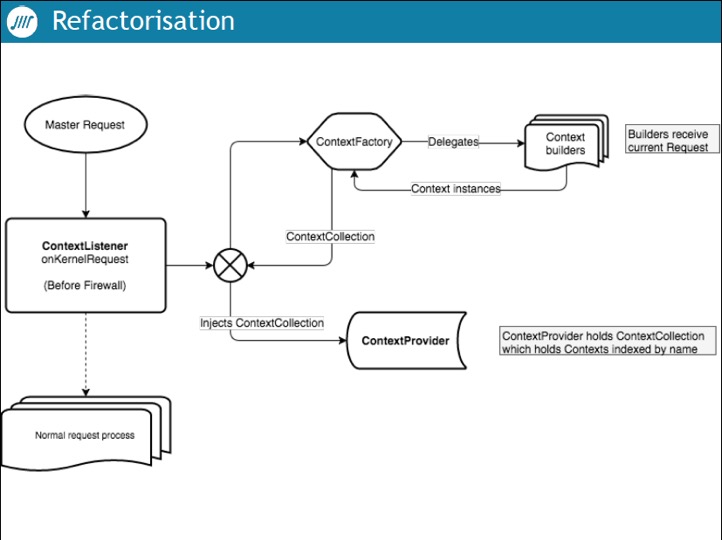
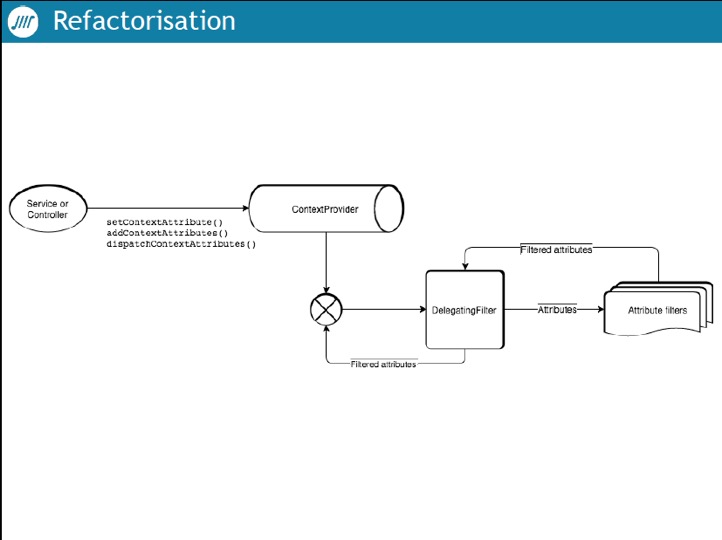

Bilan après refactorisation
La refactorisation faite, un petit bilan peut être dressé :
Avant :
- Une classe ContextUtils (d’environ 300 lignes)
- Des méthodes statiques
- Complexité élevée (indice 48)
- Evolutivité/extensibilité inexistantes
- Mélange de couches
- Impossible à tester unitairement
Après :
- 21 classes / 6 interfaces
- 10-15 lignes par classe
- Complexité faible (indice moyen 3.45)
- Extensible et maintenable
- Testable et testé
Les composants utilisés de Symfony qui ont été utilisés pour cette refactorisation:
- HttpFoundation
- HttpKernel + event dispatcher
- DependencyInjection (definitions de services + compiler passes)
- Design patterns (factory, composite, principes SOLID)
[su_spacer]
Comment la refactorisation a-t-elle été faite?
Pour vendre ce refactoring, Jérôme Vieilledent parle en général de dette technique au client. On investit au départ pour gagner du temps sur la recette, le test. On va être sûr de ce qu’on va livrer.
Le but est de faire par petits bouts, de ne pas tout faire d’un coup.
Pour cette refactorisation, beaucoup de tests fonctionnels pour le code legacy ont été écrits. L’intégration continue a été mise en place avant de faire la refacto.
Le test fonctionnel, pour Jérôme Vieilledent, est bien pour tester le rendu final côté client. Il est complémentaire des tests unitaires. Des surprises sont bien sûr arrivées (car les tests fonctionnels ne peuvent tout couvrir), notamment des cas limites. A ce moment là, l’équipe a fonctionné en TDD pour reproduire le test qui va planter.
Afin de réaliser cette refactorisation alors que des demandes d’évolution sur le legacy continuaient d’être faites, Jérôme conseille de regarder l’équilibre features legacy/refacto pour prendre de la hauteur sur le projet.
Son astuce : regarder le point d’entrée, avancer pas à pas pour voir où faire la refactorisation. Observer les besoins récurrents et voir si une mutualisation est possible.



2 comments
Bonjour, une petite vidéo sur le DDD serai pas de refus.
Hello, C’est prévu, je vais essayer d’en faire une prochainement!